
I’ve been meaning to attend a rails conference and after moving to Oahu I figured it would be a while. But now the Rails conference is coming to me! So I couldn’t pass and will be at Aloha on Rails.
I hope to see you there!
I’ve been meaning to attend a rails conference and after moving to Oahu I figured it would be a while. But now the Rails conference is coming to me! So I couldn’t pass and will be at Aloha on Rails.
I hope to see you there!

We have extracted ActivityStreams from Legaltorrents.com and released it under the BSD license.
This is a new plugin for the Rails Community that provides a customizable framework for cataloging and publishing user activity and social objects. We currently aim to provide support for microformats in HTML, Atom feeds, and compatibility with the open source DISO social networking implementation for activity discovery and consumption.
Here is a quickie for Rails 2.1:
./script/plugin install git://github.com/face/activity_streams.gitIt may work on earlier versions of Rails as well. Don’t have git:
./script/plugin install svn://rubyforge.org/var/svn/activitystreams/trunk
For further documentation here is the rdoc and the AcitivityStreams Home Page, or just show me the code.
development:
adapter: mysql
database: legaltorrents_development
username: fred
password: password
socket: /tmp/mysql.sock
production:
adapter: postgresql
database: legaltorrents_production
username: fred
password: password
host: localhost
Thanks to Ruby on Rails, transferring and converting database from one database platform to another only takes a few lines of code. There are rake tasks for dumping to YAML and back. However the existing YAML scripts I found had issues with some of our data and then failed for blobs. This script will only work with a “rails style” database. By “rails style” I mean any database where every table has a unique key named “id”.
config/database.yml found to the left.
Now both schemas must be identical. For this example let’s ensure both schemas are at the same migration:
1 2 |
rake db:migrate env RAILS_ENV=production rake db:migrate |
1 2 3 4 5 |
cd lib/tasks wget 'http://github.com/face/rails_db_convert_using_adapters/tree/master%2Fconvert.rake?raw=true' -O convert.rake # and run it rake db:convert:prod2dev |
Update Oct 1, 2008:Fixed a bug today for Rails 2.1.1. Also got rid of the hash of data that was a relic from an early version of the script that used a single model object.
Here is the full code to convert.rake:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 |
# # Convert/transfer data from production => development. This facilitates # a conversion one database adapter type to another (say postgres -> mysql ) # # WARNING 1: this script deletes all development data and replaces it with # production data # # WARNING 2: This script assumes it is the only user updating either database. # Database integrity could be corrupted if other users where # writing to the databases. # # Usage: rake db:convert:prod2dev # # It assumes the development database has a schema identical to the production # database, but will delete any data before importing the production data # # A couple of the outer loops evolved from # http://snippets.dzone.com/posts/show/3393 # # For further instructions see # http://myutil.com/2008/8/31/rake-task-transfer-rails-database-mysql-to-postgres # # The master repository for this script is at github: # http://github.com/face/rails_db_convert_using_adapters/tree/master # # # Author: Rama McIntosh # Matson Systems, Inc. # http://www.matsonsystems.com # # This rake task is released under this BSD license: # # Copyright (c) 2008, Matson Systems, Inc. All rights reserved. # # Redistribution and use in source and binary forms, with or without # modification, are permitted provided that the following conditions # are met: # # * Redistributions of source code must retain the above copyright # notice, this list of conditions and the following disclaimer. # * Redistributions in binary form must reproduce the above copyright # notice, this list of conditions and the following disclaimer in the # documentation and/or other materials provided with the distribution. # * Neither the name of Matson Systems, Inc. nor the names of its # contributors may be used to endorse or promote products derived # from this software without specific prior written permission. # # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS # "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT # LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS # FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE # COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, # INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, # BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT # LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN # ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE # POSSIBILITY OF SUCH DAMAGE. # PAGE_SIZE is the number of rows updated in a single transaction. # This facilitates tables where the number of rows exceeds the systems # memory PAGE_SIZE=10000 namespace :db do namespace :convert do desc 'Convert/import production data to development. DANGER Deletes all data in the development database. Assumes both schemas are already migrated.' task :prod2dev => :environment do # We need unique classes so ActiveRecord can hash different connections # We do not want to use the real Model classes because any business # rules will likely get in the way of a database transfer class ProductionModelClass < ActiveRecord::Base end class DevelopmentModelClass < ActiveRecord::Base end skip_tables = ["schema_info", "schema_migrations"] ActiveRecord::Base.establish_connection(:production) (ActiveRecord::Base.connection.tables - skip_tables).each do |table_name| ProductionModelClass.set_table_name(table_name) DevelopmentModelClass.set_table_name(table_name) DevelopmentModelClass.establish_connection(:development) DevelopmentModelClass.reset_column_information ProductionModelClass.reset_column_information DevelopmentModelClass.record_timestamps = false # Page through the data in case the table is too large to fit in RAM offset = count = 0; print "Converting #{table_name}..."; STDOUT.flush # First, delete any old dev data DevelopmentModelClass.delete_all while ((models = ProductionModelClass.find(:all, :offset=>offset, :limit=>PAGE_SIZE)).size > 0) count += models.size offset += PAGE_SIZE # Now, write out the prod data to the dev db DevelopmentModelClass.transaction do models.each do |model| new_model = DevelopmentModelClass.new(model.attributes) new_model.id = model.id new_model.save(false) end end end print "#{count} records converted\n" end end end end |
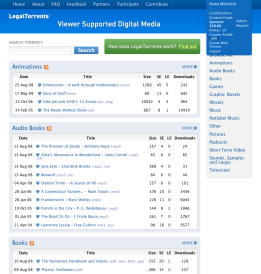
As some of you know I’ve been working full time for Matson Systems, Inc. building out LegalTorrents. I must apologize I have been neglecting parts of my blog. Fortunately, I’ve been swamped building out cool features for LegalTorrents and Matson wants to contribute back. After this caching article look for a rake task to convert a Rails app from one database platform to another, then a plugin for generating Activity Streams.
Let’s begin with conditional caching in Rails 2.1 (if 2.0, see below). Conditional action caching is a new feature of the Rails 2.1 API. First off, pre Rails 2.1 the default was disk. In rails 2.1, the default is RAM. Not going to work on limited resources:
# Put this in RAILS_ROOT/config/initializers/something.rb ActionController::Base.cache_store = :file_store, "#{RAILS_ROOT}/tmp/cache" |
class ApplicationController < ActionController::Base # ... protected # of course logged_in? needs to be defined...restful_authentication is what I recommend. def do_caching? !logged_in? && flash.empty? end |
class TorrentsController < ApplicationController # ... caches_action :show , :if => Proc.new { |controller| controller.send(:do_caching?) } |
# This cron entry that runs every 10 minutes and removes any files older than 10 minutes named '*.cache' 3,13,23,33,43,53 * * * * find /home/ltdeploy/legaltorrents/tmp/cache -mmin +10 -name '*.cache' -exec rm -f {} \; |
class CategoriesController < ApplicationController caches_action :show, :if => Proc.new { |controller| controller.send(:do_caching?) }, :cache_path => Proc.new { |c| c.params[:page] ? "#{c.request.host}.#{c.request.port}/#{c.send(:category_path,c.params[:id])}/page/#{c.params[:page]}" : "#{c.request.host}.#{c.request.port}/#{c.send(:category_path,c.params[:id])}/page/1" } |
End of Story for Rails 2.1
Now, Rails 2.0 doesn’t have :if in caches_action. To work around this we used a simple monkey patch:
class ApplicationController < ActionController::Base # ... protected # Overrides Rails core to do action_cache when not logged in...Only works in Rails 2.0 and maybe earlier def perform_caching @@perform_caching && !logged_in? && flash.empty? end |
class TorrentsController < ApplicationController # ... caches_action :show |
I have a feeling this will help some of y’all if you are getting the following error:
Sorry! Something is not quite right with the request we received from the website you are trying to use. Please try again in a few minutes. If this error persists, please contact the site administrator for the website you are trying to use. If you are the site administrator, click here to contact us.
I get this error if I try to login on my development environment because localhost:3000 just won’t cut it for Yahoo’s OpenID security policy. If I run from a production URL on port 80, say http://myutil.com/ then signin works (though I haven’t gotten Simple Registration Attribute Exchange working with Yahoo).
From the Yahoo OpenID Developers FAQ:Yahoo! Security Policies Yahoo! will only support Relying Parties running on webservers with real hostnames (IP addresses are not supported) running on standard ports (Port 80 for HTTP and Port 443 for HTTPS).
Hope this saves ya some time!

I wanted to prototype my Gibberish translations before we have an actual translator. I grabbed gibberish_translate and started copying and pasting from Google Language Tools.
After five minutes of this, I thought there has got to be a better way. I googled for an API to the Google tools, and though I found none, I did find a scraping Ruby API called rtranslate. So…
gem install googletranslaterequire 'rtranslate' def index # ...Mark's entire index method goes here unchanged if params[:filter] == "untranslated" count=0 @paginated_keys.each do |key| if ! @translated_messages[key] @translated_messages[key] = { :to => Translate.t(@en_messages[key], Language::ENGLISH, session[:translation_locale] ), :from => @en_messages[key] } end break if (count += 1) == per_page sleep 1 # Let's be nice to google end end end # end of index from gibberish_translate's translations_controller.rb |
And now Google does the work for me with the click of a mouse!
Note I did make some other changes to Mark’s code. There was a bug in translations_controller.rb in that it lost your current local when saving changes. To fix this I changed the set_translation_locale to use the session of there is no paramater:
def set_translation_locale session[:translation_locale] = params[:translation_locale] if params[:translation_locale] session[:translation_locale] = Gibberish.languages.first if Gibberish.languages if ! session[:translation_locale] end |
I also made some changes to gibberish_translate’s extractor.rb to handle Gibberish strings with default keys ("foo"[] is a valid Gibberish way of saying "foo"[:foo]):
def message_pattern(start_token, end_token)
/#{start_token}((?:[^#{end_token}](?:\\#{end_token})?)+)#{end_token}\[:*([a-z_]*)[,\]]/m
end
def add_messages(contents, start_token, end_token)
contents.scan(message_pattern(start_token, end_token)).each do |text, key|
key = text.tr('[ ]', '_').downcase if ( key == '' )
add_message(key, remove_quotes(text, end_token))
end
end
|
The final tweaks I made was to make the find system call more portable (no -regex on OpenBSD) and also have it search for strings in my gibberish_rails plugin:
def files_with_messages
`find #{dirs_to_search.join(" ")} -type f '(' -name '*rb' -or -name '*.ml' ')'`.split.map(&:chomp)
end
def dirs_to_search
%w(app config lib vendor/plugins/gibberish_rails).map { |dir| "#{RAILS_ROOT}/#{dir}" }
end
|
Peace!
Portions of the above code Copyright© 2007 Peter Marklund
With migrating from Rails 1 to Rails 2, I have tried to simplify. When I wanted to prototype a multilingual Rails application I was very intrigued by Gibberish and it’s simplicity.
As all Gibberish does is translate strings and all this plugin attempts to do is translate srings in Rails. This plugin is in a very early prototype stage but I expect it to be useful none the less.
If you want full localization of dates, numbers, the world etc. check out some of the other more mature localization plugins.
If you are trying to localize your Rails strings with Gibberish, then this plugin is for you.
When I set out I didn’t even expect to make a plugin, just write some simple ruby in my project. However, it turns out there is a reason for the bloat in localization plugins…rails was never designed to be localized and has some quirks that lead to the necessity of overriding large core rails methods. The rails core team is obviously aware the problem and are working on a solution with ticket 9726. I’m hoping Rails ticket 9726 will make it to edge and then I’ll be able to simplify this plugin.
Without further adieu, I give you gibberish_rails.
Here is a link to the RDoc.
Quickie instructions (includes install for Gibberish).
./script/plugin install svn://errtheblog.com/svn/plugins/gibberish
./script/plugin install http://svn.myutil.com/projects/plugins/gibberish_rails/Please read the README in it’s entirety before using.
Now you must translate your strings. I recommend using gibberish_translate. My next article will be on automatic prototyping translations with gibberish_translate and Google Language Tools.
![]()
OpenID makes sense. Dr. Nick’s multi-OpenIDs per user example app makes even more sense.
In the middle of integrating it into my project, gem-1.0.1 came out and broke ruby-openid-1.1.4. Dr. Nick’s great example no longer worked!
A little digging and I found Dr. Nick’s example uses the standard open_id_authentication. That has a patch to work on ruby-openid-2.0.2 and rails 2 which can be found here.
So in a nutshell, I grabbed openidauth_multiopenid-0.3.2 from Dr. Nick, removed a bunch of stuff from vendor plugins. Updated Rakefile, config/boot.rb, and config/environment.rb for rails 2.0.2. Patched vendor/plugins/open_id_authentication for ruby-openid-2.0.2. Regenerated db/migration/002_add_open_id_authentication_tables.rb. And installed ruby-openid-2.0.2 as a system gem.
As a little code is worth more than a thousand words, here is Dr. Nick’s example application fully ported to rails 2.0.2 in ZIP and TAR.gz.
For my port of Dr. Nick’s example above to work, you will need rails-2.0.2 and ruby-openid-2.0.2 installed as a gems.
Security Update: January 4th, 2007 I noticed the example adds edit, update, and destroy to users_controller.rb usingparams[:id] thus allowing any logged in user to edit, update, and destroy any user of the system. To fix, simply change the first line of edit, update, and destroy to use the current logged in user (i.e. @user = User.find(self.current_user.id)).
@user_openids = UserOpenid.find_all_by_user_id(@user.id). I think it’s time I put this example under SVN and apply these security upates…
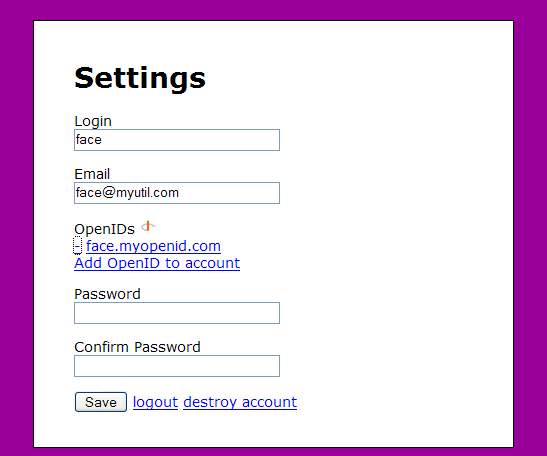
http://drnicwilliams.com/2007/07/26/sample-app-rails-multiple-openids-per-user/
http://dev.rubyonrails.org/ticket/10604
http://openidenabled.com/ruby-openid/
http://svn.rubyonrails.org/rails/plugins/open_id_authentication/
http://openid.net/
